M.I.T Media Lab : Mendeteksi jenis kelamin berdasarkan suara vokal
 |
| ilustrasi logo M.I.T |
Kabar gembira datang dari M.I.T (Mistik Institute of Technology). Seorang staff M.I.T yang tidak ingin disebutkan namanya. Sedang berbaik hati bersedia memberikan sebuah software secara sukarela beserta lisensinya demi kemaslahatan orang banyak selama jangka waktu maksimal 30 hari (free trial) untuk keperluan "education" semata.
Keberadaan software ini jelas membantu memecahkan misteri yang selama ini berkembang dikalangan netizen youtube. Harapannya desas desus gosip miring segera terungkap.
 | |||
| ilustrasi detektif 3gp |
Oke langsung saja. Ogut mengambil random sampling dari youtube sebanyak 9 biji. Kemudian ogut lakukan pemotongan suara untuk mengambil suara vokal yang cukup jelas serta suara noise (baground keramaian) yang cukup kecil dengan harapan agar pendeteksian dapat berjalan lancar tanpa ada halangan. Berikut ini Videonya...
-------[data sampling 1]-------
 |
| Jeng Anggita Sari = CEWEK = BENAR |
win_gender=Female
win_score=89.775
female_score=89.775
male_score=10.225
[waveform_filter]
filter_enabled=true
silence_length=0.000 s (0.00 %)
technical_length=0.060 s (0.21 %)
intermittent_length=0.000 s (0.00 %)
speech_length=28.815 s (100.00 %)
total_filtered_length=0.000 s (0.00 %)
technical_nosil_ratio=0.21 %
-------[data sampling 2]-------
 |
| Jeng Devi Liu = CEWEK = BENAR |
win_gender=Female
win_score=93.815
female_score=93.815
male_score=6.185
[waveform_filter]
filter_enabled=true
silence_length=31.260 s (11.04 %)
technical_length=7.545 s (2.66 %)
intermittent_length=0.000 s (0.00 %)
speech_length=252.225 s (89.04 %)
total_filtered_length=31.050 s (10.96 %)
technical_nosil_ratio=2.99 %
-------[data sampling 3]-------
 |
| Jeng FDJ Varra = CEWEK = BENAR |
win_gender=Female
win_score=98.999
female_score=98.999
male_score=1.001
[waveform_filter]
filter_enabled=true
silence_length=0.000 s (0.00 %)
technical_length=8.760 s (19.92 %)
intermittent_length=0.000 s (0.00 %)
speech_length=37.170 s (84.54 %)
total_filtered_length=6.795 s (15.46 %)
technical_nosil_ratio=19.92 %
-------[data sampling 4]-------
 |
| Kak Vicky = COWOK = BENAR |
win_gender=Male
win_score=84.182
female_score=15.818
male_score=84.182
[waveform_filter]
filter_enabled=true
silence_length=0.000 s (0.00 %)
technical_length=4.905 s (9.90 %)
intermittent_length=0.000 s (0.00 %)
speech_length=49.170 s (99.24 %)
total_filtered_length=0.375 s (0.76 %)
technical_nosil_ratio=9.90 %
-------[data sampling 5]-------
 |
| Kak Afgan = EMBUH = ???? (gender = unknown, male score = 70.236%) |
win_gender=Unknown
win_score=none
female_score=29.764
male_score=70.236
[waveform_filter]
filter_enabled=true
silence_length=0.000 s (0.00 %)
technical_length=0.075 s (0.25 %)
intermittent_length=0.000 s (0.00 %)
speech_length=30.270 s (100.00 %)
total_filtered_length=0.000 s (0.00 %)
technical_nosil_ratio=0.25 %
-------[data sampling 6]-------
 | |
| GEBBY VESTA = CEWEK = BENAR |
win_gender=Female
win_score=96.874
female_score=96.874
male_score=3.126
[waveform_filter] <<<< FILE 1
filter_enabled=true
silence_length=0.000 s (0.00 %)
technical_length=0.420 s (0.71 %)
intermittent_length=0.000 s (0.00 %)
speech_length=59.475 s (100.00 %)
total_filtered_length=0.000 s (0.00 %)
technical_nosil_ratio=0.71 %
[results] <<<< FILE 2
win_gender=Female
win_score=94.517
female_score=94.517
male_score=5.483
[waveform_filter] <<<< FILE 2
filter_enabled=true
silence_length=0.000 s (0.00 %)
technical_length=0.675 s (1.30 %)
intermittent_length=0.000 s (0.00 %)
speech_length=51.750 s (100.00 %)
total_filtered_length=0.000 s (0.00 %)
technical_nosil_ratio=1.30 %
-------[data sampling 7]-------
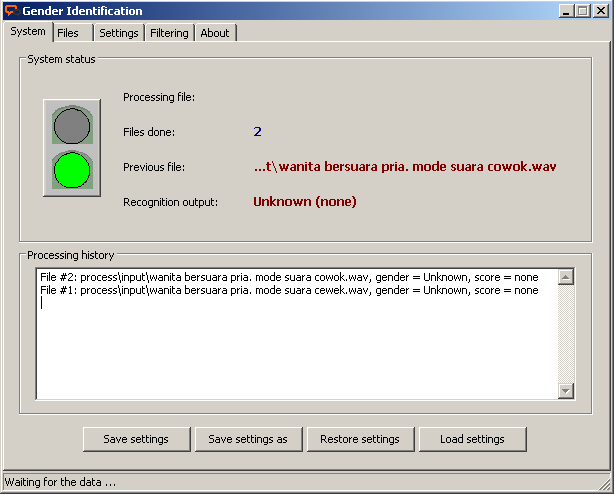 |
| Wanita Bersuara Pria = UNKNOWN = ???? |
[results] <<<< MODE SUARA COWOK
win_gender=Unknown
win_score=none
female_score=68.456 <<<< diatas 50% = horror
male_score=31.544 <<<< dibawah 50% = suram
[waveform_filter] <<<< MODE SUARA COWOK
filter_enabled=true
silence_length=0.000 s (0.00 %)
technical_length=0.450 s (0.89 %)
intermittent_length=0.000 s (0.00 %)
speech_length=50.775 s (100.00 %)
total_filtered_length=0.000 s (0.00 %)
technical_nosil_ratio=0.89 %
File Kedua = Mode Suara Cewek.
[results] <<<< MODE SUARA CEWEK
win_gender=Unknown
win_score=none
female_score=59.225 <<<< diatas 50% = correct
male_score=40.775 <<<< mendekati 50% = horror
[waveform_filter] <<<< MODE SUARA CEWEK
filter_enabled=true
silence_length=0.000 s (0.00 %)
technical_length=0.180 s (0.56 %)
intermittent_length=0.000 s (0.00 %)
speech_length=31.890 s (100.00 %)
total_filtered_length=0.000 s (0.00 %)
technical_nosil_ratio=0.56 %
-------[data sampling 8]-------
win_gender=Unknown <<<< ????
win_score=none
female_score=76.996 <<<< Aman ndan, eh... aman gan....
male_score=23.004
[waveform_filter]
filter_enabled=true
silence_length=63.735 s (46.70 %)
technical_length=0.180 s (0.13 %)
intermittent_length=0.000 s (0.00 %)
speech_length=75.510 s (55.32 %)
total_filtered_length=60.975 s (44.68 %)
technical_nosil_ratio=0.25 %
-------[data sampling 9]-------
win_gender=Female <<<< hahahah
win_score=87.981
female_score=87.981 <<<< hahahah
male_score=12.019
[waveform_filter]
filter_enabled=true
silence_length=53.595 s (39.69 %)
technical_length=2.190 s (1.62 %)
intermittent_length=0.000 s (0.00 %)
speech_length=92.430 s (68.44 %)
total_filtered_length=42.615 s (31.56 %)
technical_nosil_ratio=2.69 %
Failure detection and identification
Kesalahan tanpa disengaja senantiasa hadir saat proses uji coba tengah berlangsung. Kesalahaan deteksi ini dikarenakan input data yang salah / kurang sesuai dengan minimun requirement sesuai permintaan software atau memang murni karena kesalahan kalkulasi (algoritma) yang ditimbulkan oleh software itu sendiri. Ogut sendiri juga tidak tahu.
data sampling 5 : Suara noise (baground vokal) milik kak afgan pelantun lagu sadis bisa dibilang lumayan ramai. Hasilnya, status = Unknown, akan tetapi masih bisa diselamatkan angka male_score=70.236% yang cukup bagus. Selamat ya kak afgan :ngacir
data sampling 7 : Satu orang yang sama namun memiliki suara yang berbeda, file pertama ketika mode suara cewek. file kedua ketika mode suara cowok. Dan juga suara noise (baground penonton & musik) terlalu ramai. Hasilnya, status = unknown. (btw status unknown disebabkan karena noise terlalu tinggi atau karena memang gender suaranya setengah cewek & setengah cowok alias banci kaleng detected. hahah)
data sampling 8 : Suara noise (baground vokal) lumayan cukup bersih. Hanya saja suara vokalis "duo drible" kurang begitu jelas didengar. Doi cuman nyanyi sambil mendesah desah, "hay mas bro.. hai mas bro kemana ajah.... Hasilnya, status = Unknown, akan tetapi female_score=76.996% cukup lumayan bagus. .
data sampling 9 : ini kayak'e om Maximbady sedang mengalami apes (masuk kategori 1% orang yang mengalami sial). Om maximbady dapat dipastikan seorang pria sejati, namun si software mendeteksi om maximbady sebagai gender cewek, female_score=87.981%. Secara teknis, cieeee Pronounciation, Dialect, Logat atau apalah namanya, suaranya om maximbady memang rada aneh. hahah http://www.quora.com/YouTube-Personalities/Who-is-maximbady
Kesimpulannya, empat data (dari total sebanyak 9 data) yang mengalami kesalahan deteksi bukan lantaran kesalahan si software, melainkan karena kualitas datanya aja yang kurang mantap.
- Satu data dikarenakan baground noise terlalu tinggi,
- Satu data karena noise terlalu tinggi / memang karena faktor banci kaleng.
- Dua data berikutnya karena logat suaranya kurang lazim (mendesah, cedal, dll) sehingga dianggap aneh oleh si software.
Penutup
 |
| ilustrasi kasus ditutup |
Jadi, hasil test "image recognition", si doi mendapatkan skor 70% ~ 88% terdeteksi berjenis kelamin cewek.
Lalu, hasil test "speech/voice recognition", si doi mendapatkan skor 94.517% ~ 96.874% terdeteksi berjenis kelamin cewek.
Skeptis :
Apabila guys masih skeptis dengan tidak mempercayai kesahihan & akurasi sebuah algoritma yang ada pada software "image recognition" & "speech/voice recognition". Lantas berharap ingin hasil yang sangat akurat dan realistis, sebaiknya menanyakan secara langsung kepada yang bersangkutan. Eh geb, kamu tuh sebenernya cewek/cowok sih ????. hahah *siap-siap kena gampar
#File Example & Log.txt hasil ujicoba di atas.
https://www.dropbox.com/sh/mxjrv6kn4amasmz/AAAwfNogYd_cMIUNZSlf3sFca?dl=0
Video Bonus (intermezo)
Update :
Apabila guys iseng ingin mencoba dan berharap mendapatkan hasil yang bagus, silahkan mengikuti "rule of thumb" di bawah ini. (mengutip makalah analisis karakteristik suara manusia berdasarkan frekuensi fundamental dan tingkat usia pada pelajar sltp dan sma.)
Ada beberapa faktor yang mempengaruhi hasil penelitian mengenai karakteristik suara manusia berdasarkan frekuensi fundamental yaitu :
1. Kondisi lingkungan saat perekaman.
Kondisi ruangan saat perekaman tidak kedap suara, sehingga memungkinkan adanya suara-suara lain yang ikut terekam oleh komputer. Derau ini mengganggu suara asli siswa yang direkam, dibutuhkan ruangan perekaman yang seminimal mungkin bebas derau.
2. Kondisi suara responden.
Kondisi suara responden sangat berpengaruh terhadap nilai frekuensi fundamental yang dicari. Pada saat perekaman, terdapat responden yang sedang sakit batuk atau flu, sehingga sangat mempengaruhi suara aslinya saat tidak sakit. Responden diharapkan dalam kondisi normal saat perekaman sinyal suara.
3. Letak mikrofon.
Perekaman suara dilakukan secara bertahap maka dalam peletakan mikrofon tidak selalu sama. Jarak dan sudut mikrofon sangat mempengaruhi sinyal suara yang dihasilkan. Untuk mengatasi hal ini bisa dilakukan dengan cara mengatur jarak mikrofon dan sudut mikrofon agar relatif sama untuk tiap kali perekaman.
4. Cara perekaman sinyal suara.
Perekaman sinyal suara yang tepat juga ikut mempengaruhi akurasi nilai frekuensi fundamental. Cara perekaman yang baik adalah diucapkan secara wajar dan tidak dibuat-dibuat, suara diucapkan tidak
terlalu keras atau terlalu lemah.
Referensi :
- http://pencopet-cinta.blogspot.com/2015/01/mit-menyan-institute-of-technology.html
- http://download.portalgaruda.org/article.php?article=59681&val=4485
- http://yudistira.lecture.ub.ac.id/files/2014/04/Klastering-Suara-Laki-Laki-dan-Perempuan-Menggunakan-Algoritma-K-Means-Berdasarkan-Hasil-Ekstraksi-FFT.pdf



Komentar
Posting Komentar
Silahkan diisi...